Cryptocurrency
Trading
Algorith
Trading
Algorith

This project was developed as my Master's thesis at HSE. The goal was to create an automated trading system capable of generating and validating signals with possible order execution.
It utilizes the two-step approach to trading: firstly, various uncorrelated strategies generate buy and sell signals based on the conditions of the market. After that, all the generated signals are validated by the classification model in order to sort-out potentially misleading signals.
It utilizes the two-step approach to trading: firstly, various uncorrelated strategies generate buy and sell signals based on the conditions of the market. After that, all the generated signals are validated by the classification model in order to sort-out potentially misleading signals.
Overview
The system utilizes default OHLCV data, accessible via API from any exchange in a unified format. For each strategy the indicators were calculated using TA-Lib, TA and custom functions made by me or coded from open source TradingView indicators.
For the second step the market state was defined using the different indicators, their lags and percentage changes. The final number of columns for classification was 222.
For the second step the market state was defined using the different indicators, their lags and percentage changes. The final number of columns for classification was 222.
Data Acquisition
Grid Search
Developing good strategies is the key factor in making the bot profitable, because this is the starting point for all the future signal validation. Overall, trading strategies can be divided into 3 categories:
Unfortunately, I will not share my setups and trading conditions, but will provided the main ideas of optimisations and results. However, I can say, that the two main strategies I'm using now are Triple-Double (breakout strategy) and Discounted Supertrend (trend following strategy).
- Trend Following - when we try to identify trend before it happened in order to get profits from hopping on it early
- Breakout - when we try to find key levels which holds a price within a range and wait until they are broken
- Mean Reversion - when we find a high deviation of the price from its smoothed mean and try to gain profit on its reversal to the "optimal" level
Unfortunately, I will not share my setups and trading conditions, but will provided the main ideas of optimisations and results. However, I can say, that the two main strategies I'm using now are Triple-Double (breakout strategy) and Discounted Supertrend (trend following strategy).
1-st Step: Strategies
To maximise the profits, we need to find optimal parameters for the strategies, which can be timeframe, windows or other arguments for indicators. One the most common ways to do this is to apply GridSearch. The idea behind it is very simple: we define a net of values for parameter and try all the possible combinations between them. After this, we can see, what combinations perform better and use them for further evaluation.
The key metrics I'm tracking during GridSearch are:
Also, to sort the results, I used a custom metric, which is ROI × AVG Profit per Trade. This metrics helps to leverage the total profitability of the combination and its stability (because the lower average profitability the more unstable the combination).
After applying GridSearch, the results were following:
-- INSERT GS TABLE --
The key metrics I'm tracking during GridSearch are:
- Total ROI
- AVG Profit per Trade
- Number of Trades
Also, to sort the results, I used a custom metric, which is ROI × AVG Profit per Trade. This metrics helps to leverage the total profitability of the combination and its stability (because the lower average profitability the more unstable the combination).
After applying GridSearch, the results were following:
-- INSERT GS TABLE --
Parameter Validation
After finding optimal parameters it is crucial to understand why they are optimal. GridSearch focuses on certain metrics, but these combinations also require examination for their money-generating potential. Important metrics include:
-- INSERT METRICS TABLE --
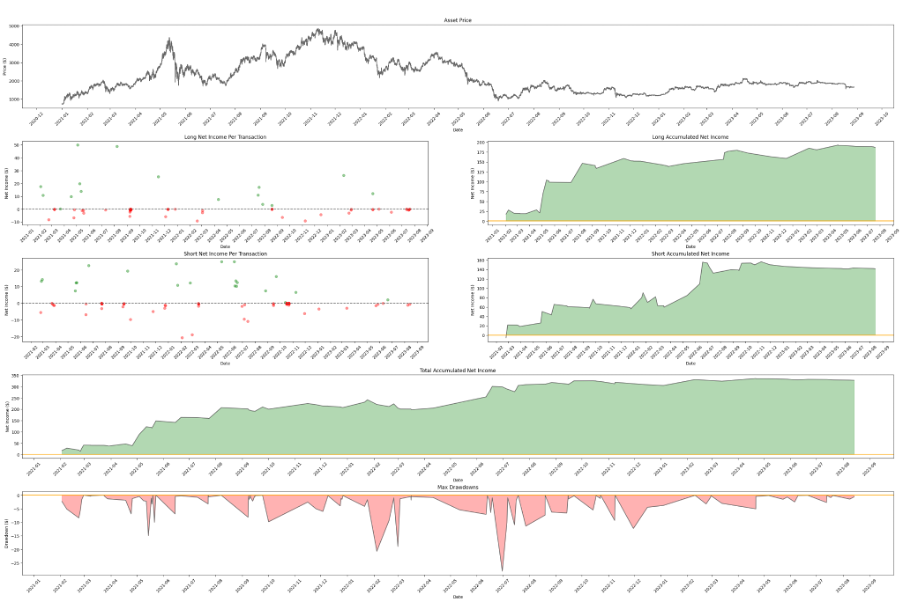
Visual representation can also help to understand the trade structure. Most common thing to look on are
Here is an example of such visualisation for Discounted Supertrend strategy:
If everything looks good for all the strategies, the next step is to apply ML filtering to decrease risk and increase profitability.
-- INSERT METRICS TABLE --
Visual representation can also help to understand the trade structure. Most common thing to look on are
- Asset price - to understand the state of the price movement at the signal timing
- Net income per transaction - scatterplot, which helps to understand the profitability of trades by position type
- Accumulated net income - how different positions perform over time
- Total accumulated net income - how our portfolio will act if we traded this combination
- Drawdowns - the structure of position being held and precision of signals
Here is an example of such visualisation for Discounted Supertrend strategy:
If everything looks good for all the strategies, the next step is to apply ML filtering to decrease risk and increase profitability.
Model development
Basic model
Given the length of the dataset (not much more than 500 trades), I used Cross-Validation not to lose any data for splitting. Also, I tested 7 models, which were:
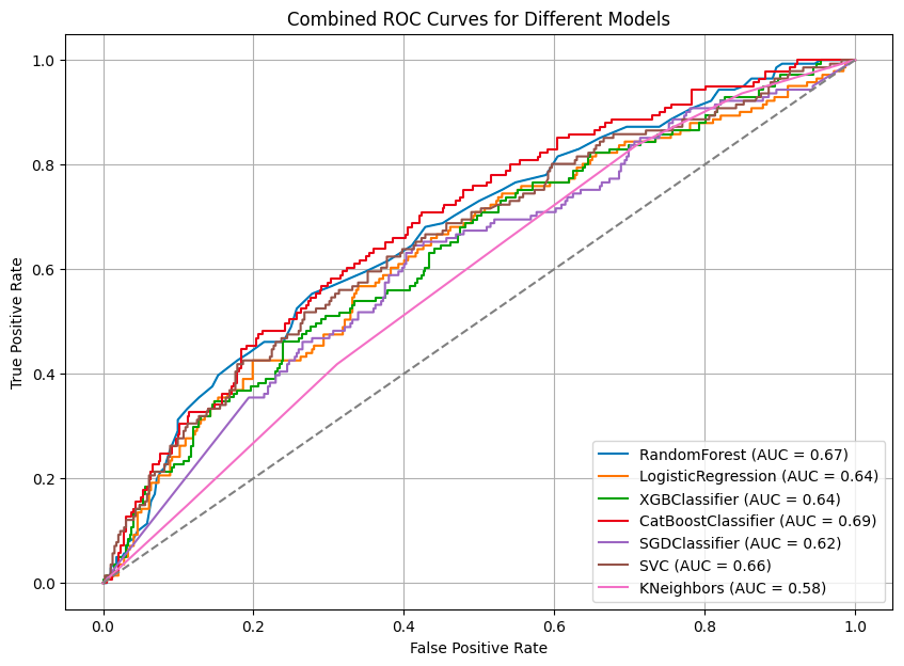
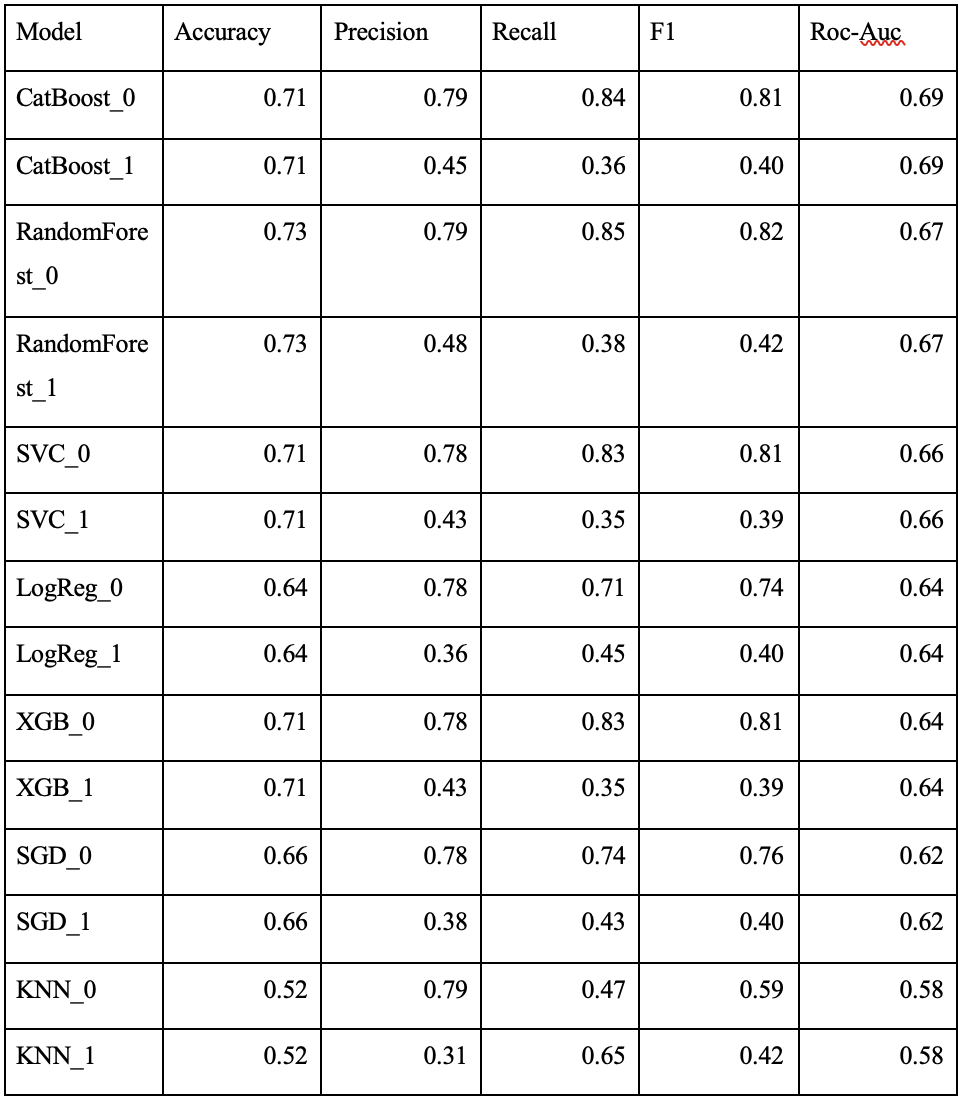
Here you can see the summarised results of performance by key metrics:
The model effectively filters "bad" trades, though at the cost of remove also some of the "good" trades. This trade-off is inherent, as perfect filtering is unattainable with the given market state information. However, the model stabilises and increases the average profit per trade by over 150%, significantly improving robustness.
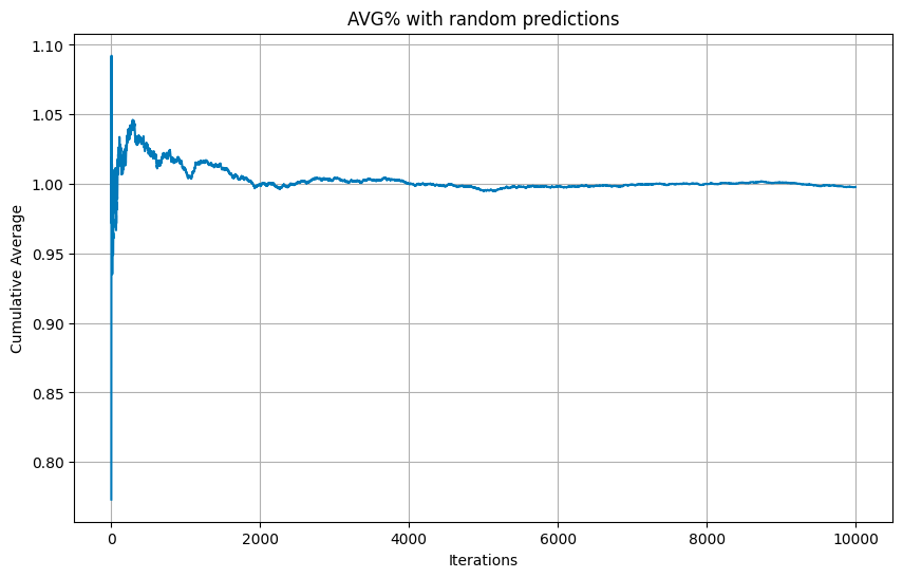
To be sure, that this is not a random increase, I conducted a LLN simulation. The idea behind it was to utilise law of large number and get the average trade profit if we randomly filter-out trades based on the ration between "good" and "bad". As can be seen, the average profit per trade does not increased, giving one more sign of the model's effectiveness.
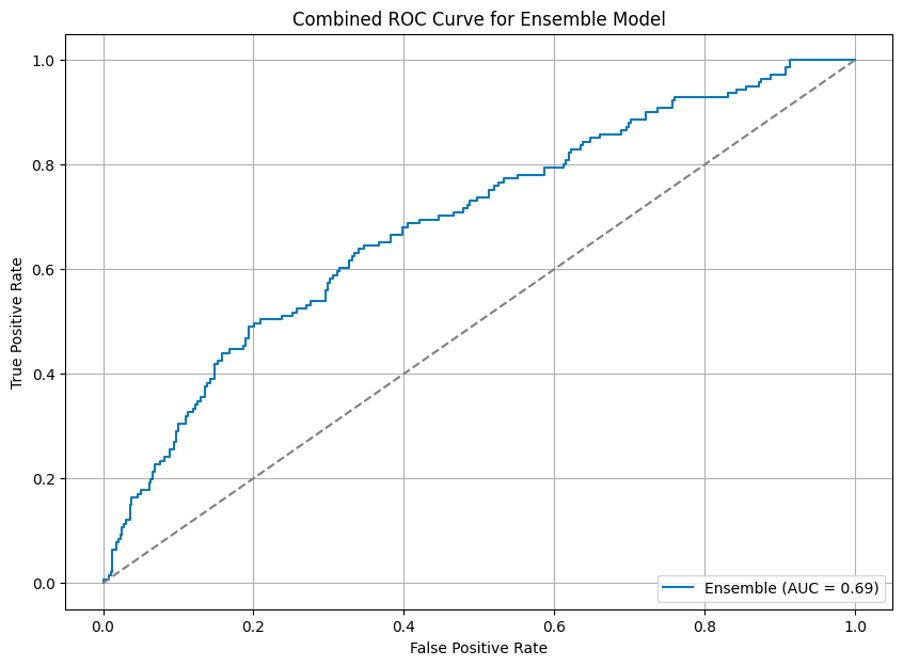
Ensembling
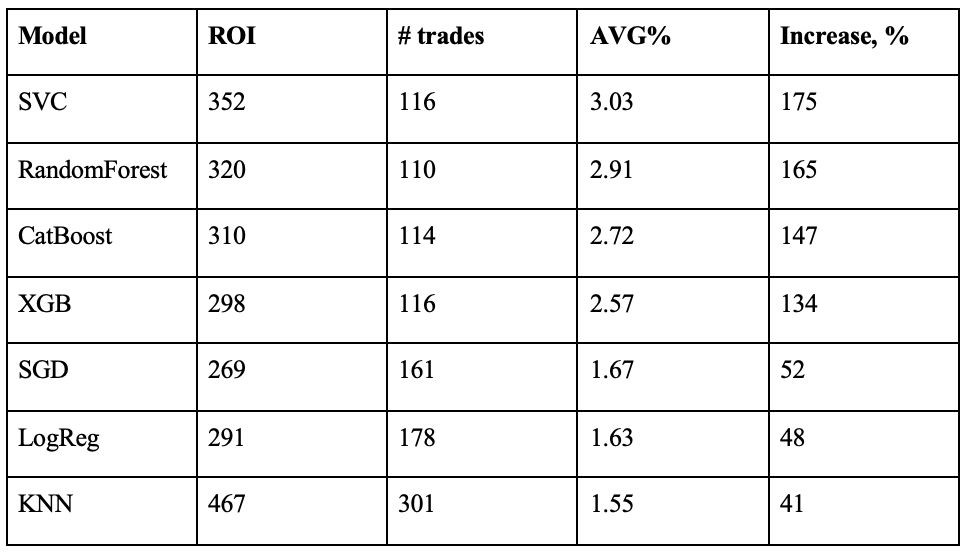
Another thing to try was to ensemble top performing models. The idea is simple - working together, they will cover each one's errors and will help to increase the profit even more. Here is the results of conduction such an approach:
As can be seen, it increased the average profit per trade even more. However, the standard deviation also increased, so we can draw a conclusion, that, despite being more profitable, model became less stable, which is a very natural result considering risk-profit tradeoff.
Tuning
I also performed a try to tune the top models, however, this does not increase profit and not reduced standard deviation, that is why I will not bother you with this.
Given the length of the dataset (not much more than 500 trades), I used Cross-Validation not to lose any data for splitting. Also, I tested 7 models, which were:
- Random Forest Classifier
- Logistic Regression
- XGBoost Classifier
- CatBoost Classifier
- SGD Classifier
- Support Vector Classification
- K Neighbors Classifier
Here you can see the summarised results of performance by key metrics:
The model effectively filters "bad" trades, though at the cost of remove also some of the "good" trades. This trade-off is inherent, as perfect filtering is unattainable with the given market state information. However, the model stabilises and increases the average profit per trade by over 150%, significantly improving robustness.
To be sure, that this is not a random increase, I conducted a LLN simulation. The idea behind it was to utilise law of large number and get the average trade profit if we randomly filter-out trades based on the ration between "good" and "bad". As can be seen, the average profit per trade does not increased, giving one more sign of the model's effectiveness.
Ensembling
Another thing to try was to ensemble top performing models. The idea is simple - working together, they will cover each one's errors and will help to increase the profit even more. Here is the results of conduction such an approach:
As can be seen, it increased the average profit per trade even more. However, the standard deviation also increased, so we can draw a conclusion, that, despite being more profitable, model became less stable, which is a very natural result considering risk-profit tradeoff.
Tuning
I also performed a try to tune the top models, however, this does not increase profit and not reduced standard deviation, that is why I will not bother you with this.
Generating feature
One of the key methods was to understand, how to split the target variable into classification bins. I come up with the idea, that we define 2 main classes: 1 - if the ROI for the trade was more than 1% and 0 otherwise. 1% is determined to be optimal value in terms of filtering unprofitable trades and not losing profitable trades due to misclassification.
As said before, various indicators were used to provide most possible information about market conditions to the models. Here is a list of them:
Using ACF/PACF analysis, the best windows for lags and percentage changes were determined to be 1, 2, 5, 10, 15 and 20.
Resampling
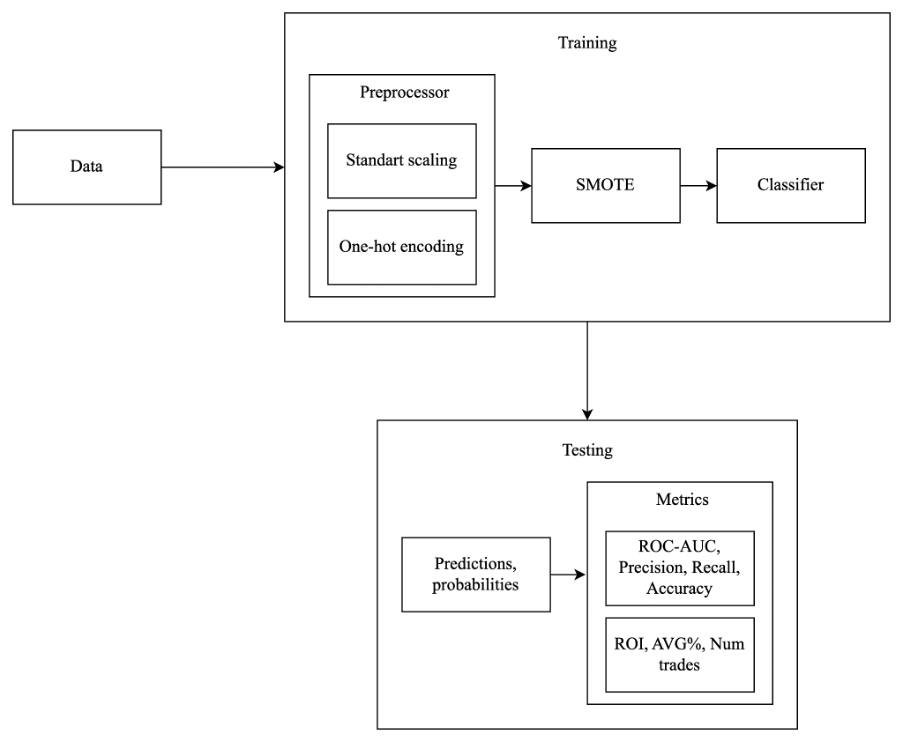
Due to the fact, that the amount of unprofitable trades was higher, than the profitable (30% vs 70%), i.e. dataset was imbalanced, I used SMOTE resampling technique to balance it. Also, Scaling and One-Hot Encoding were used to format the input data in a proper way, because financial indicators are mostly have different units of measurement.
Overall, the final pipeline was looking like this:
One of the key methods was to understand, how to split the target variable into classification bins. I come up with the idea, that we define 2 main classes: 1 - if the ROI for the trade was more than 1% and 0 otherwise. 1% is determined to be optimal value in terms of filtering unprofitable trades and not losing profitable trades due to misclassification.
As said before, various indicators were used to provide most possible information about market conditions to the models. Here is a list of them:
- Trend-following indicators: Moving Average Convergence Divergence (MACD), Average Directional Index (ADX)
- Volatility indicators: Bollinger Bands, Average True Range (ATR), Standard Deviation (STD)
- Support and Resistance Indicators: Pivot Points, Fibonacci Retracement
- Oscillators: Relative Strength Index (RSI), Stochastic Oscillator, Commodity Channel Index (CCI), Williams %R, Rate of Change (ROC)
Using ACF/PACF analysis, the best windows for lags and percentage changes were determined to be 1, 2, 5, 10, 15 and 20.
Resampling
Due to the fact, that the amount of unprofitable trades was higher, than the profitable (30% vs 70%), i.e. dataset was imbalanced, I used SMOTE resampling technique to balance it. Also, Scaling and One-Hot Encoding were used to format the input data in a proper way, because financial indicators are mostly have different units of measurement.
Overall, the final pipeline was looking like this:
Data Preprocessing
When the strategies are finalised, the next step if to improve them. Due to the market complexity, it is hard to create a strategy which will act good during all types of markets, so it is crucial to trade them only when they have a competitive advantage in understanding patterns. The ML algorithm is aimed to determine such conditions and filter-out trades, which are not connected with them. That is why each strategy has a different classifier, trained only on their trades.
2-nd Step: ML Classification
The performance of the algorithm can considered to be good. At least, I'm using in real life and it showed, that it can generate profit. There are many things, which can (and will) be added, like money management, portfolio optimisation, etc.
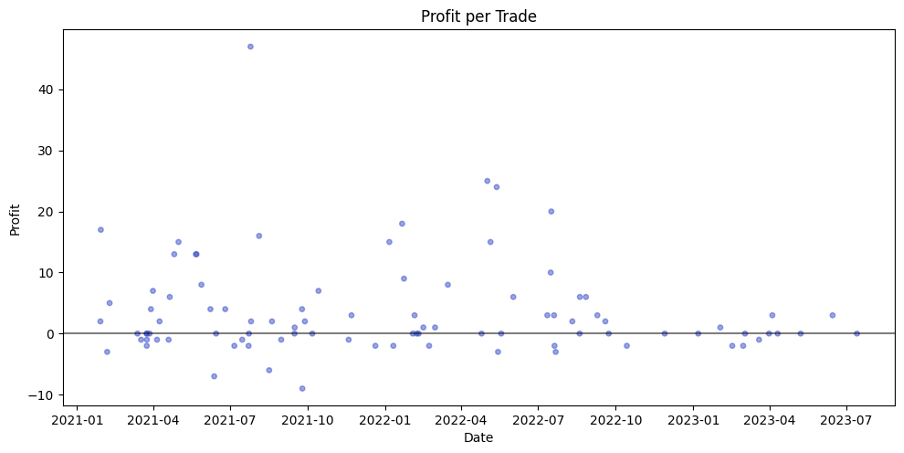
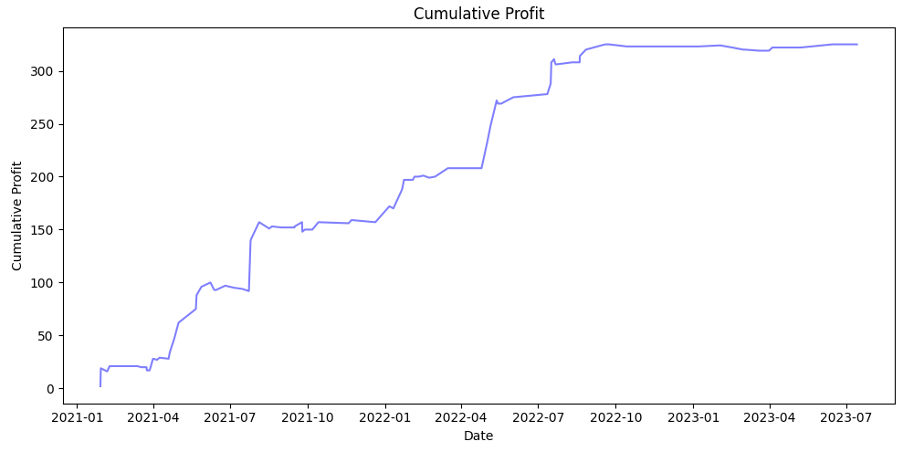
Overall, the graphs describes everything best and they are following:
The scatter plot shows, that despite a big amount of trades around 0% ROI, the amount and "quality" of positive trades are giving an ability to increase initial capital. Also, the cumulative profit (uncompounded) is always rising.
Overall, the graphs describes everything best and they are following:
The scatter plot shows, that despite a big amount of trades around 0% ROI, the amount and "quality" of positive trades are giving an ability to increase initial capital. Also, the cumulative profit (uncompounded) is always rising.
Results
